Silei Huo

Data-driven problem solver with extensive experience in Banking and Technology (Payments), focusing on Strategic Planning, Product Management, and Data Analytics. MBA from London Business School.
Data Science | FinTech | Payment Processing | Banking
View My LinkedIn Profile
Online Payment Fraud Detection
Project Background
Applying machine learning models on a the e-commerce transactions dataset, which contains a wide range of features from device type to product features, to detect fraudulent transactions and improve the efficacy of alerts to reduce fraud loss as well as save the hassle of false positives.
 Photo by Paul Felberbauer on Unsplash
Photo by Paul Felberbauer on Unsplash
Data Source & Description
The data comes from real-world e-commerce transactions, source: IEEE-CIS Fraud Detection
- Train Set: 590,540 transactions with 433 features
- Test Set: 506,691 transactions with 433 features
- Data Description:
TransactionDT: timedelta from a given reference datetime (not an actual timestamp)TransactionAMT: transaction payment amount in USDProductCD: product code, the product for each transactioncard1-card6: payment card information, such as card type, card category, issue bank, country, etc.addr: addressdist: distance- P_ and (R__) emaildomain: purchaser and recipient email domain
C1-C14: counting, such as how many addresses are found to be associated with the payment card, etc. The actual meaning is masked.D1-D15: timedelta, such as days between previous transaction, etc.M1-M9: match, such as names on card and address, etc.- identity information – network connection information (IP, ISP, Proxy, etc) and digital signature (UA/browser/os/version, etc) associated with transactions.
PART 1 - Data Wrangling & EDA
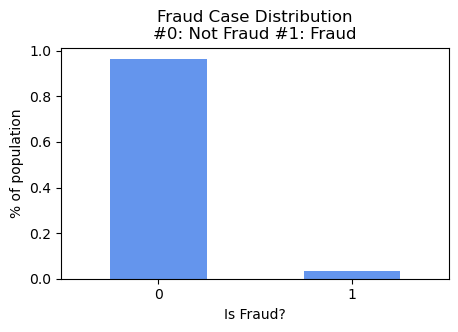
Overall Target Variable(IsFraud) & Transaction Amount Distribution
- In the training dataset, there is ~3.5% fraud cases, which is a highly imbalanced datase
- Majority of the payment amount is less than 200, while even higher proportion of fruad transactions are within and around 100
| Percentage of Fraudulent Transactions | Transaction Amount Distribution across Two Classes |
|---|---|
 |
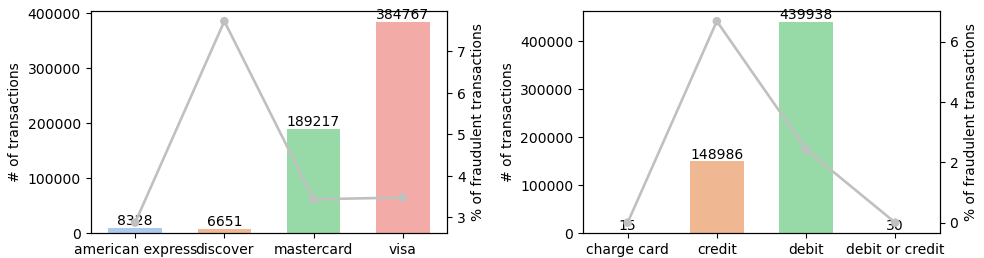
Card Types
- Majority payments are through Visa and MasterCard, accounts for 65% and 32% respectively, with roughly ~3.5% of fraudulent transactions, while discover has the highest percentage of fraud cases, which is close to 8%
- Over 74.5% of transactions are paid via debit card, while 25.2% are done with credit card which contains highest percentage(close to 7%) of fraudulent transactions
| Transaction Distribution across Card Types |
|---|
 |
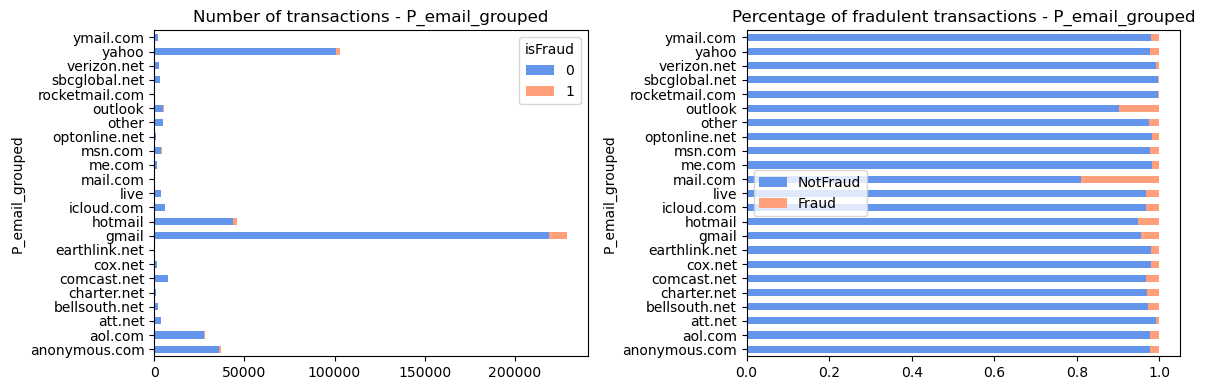
Email Domains
- Top purchaser email domains including gmail (46%), yahoo(20%), hotmail(9%) of the known transactions
- Among the top email domains, ‘mail.com’ with highest percentage of fraud cases ~20%, while ‘outlook.com’ contains ~10%
| Transaction Distribution across Email Domains |
|---|
 |
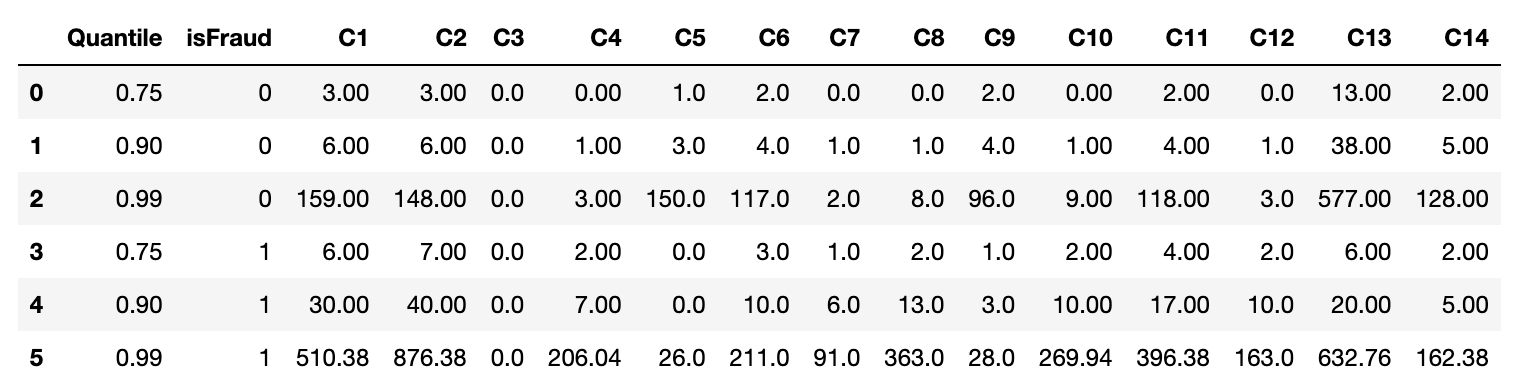
Counting Information
(such as how many addresses are found to be associated with the payment card)
Since the data for couting information is heavily right skewed, thus looking further into the higher quantile values, and it’s interesting to find that for most of the columns, fraud class has much higher values and only columns C4 & C9 are opposite.
| Quantiles for Counting Variables |
|---|
 |
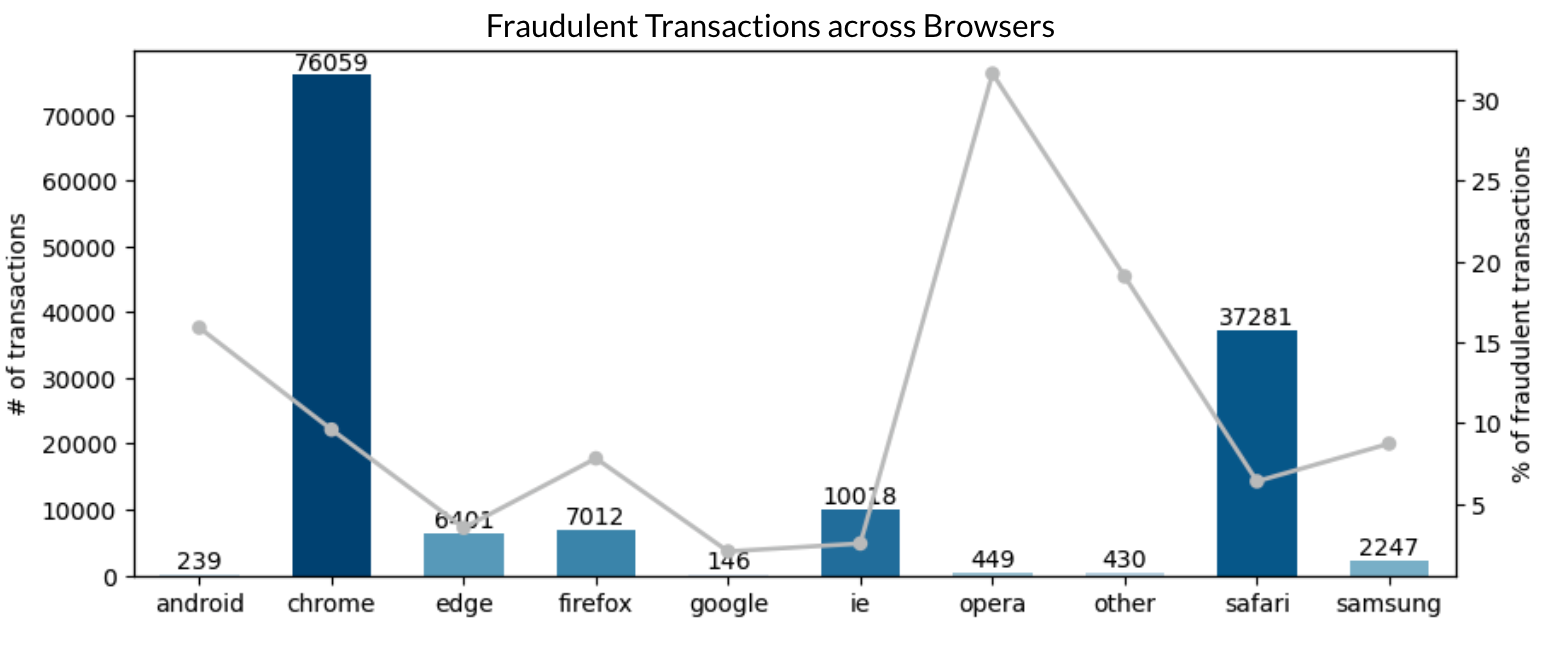
Web - Browser Types
- Opera’s percentage of fraudulent transactions is the highest among various categories with over 30%, while Chrome is the most popular web browser.
PART 2 - Analysis & Modeling
Model Performance Comparison
- Applied XGBoost and LGBM classification models to detect fraudulent online transactions. After initial rounds of hyperparameter tuning, LGBM(AUC score: 0.94) outperformed a bit compared with XGBoost model(AUC score: 0.93).

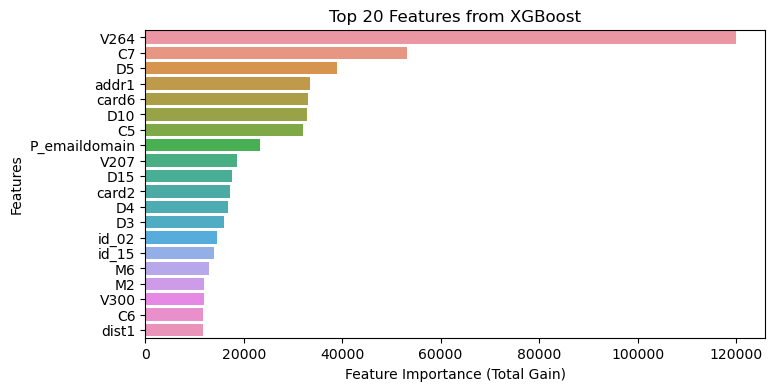
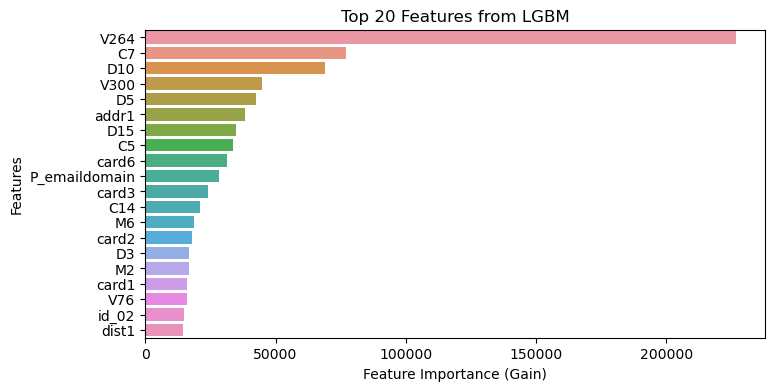
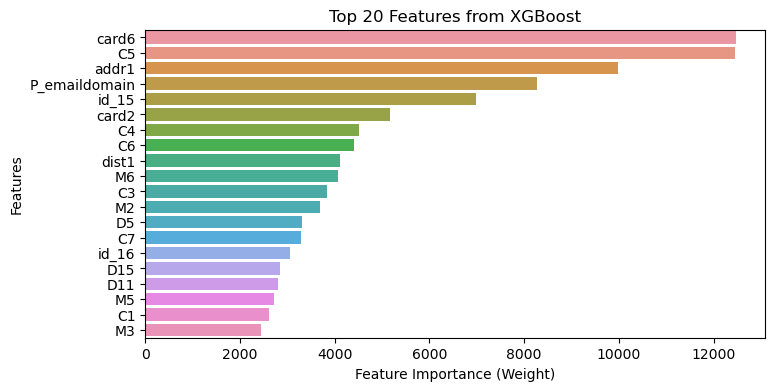
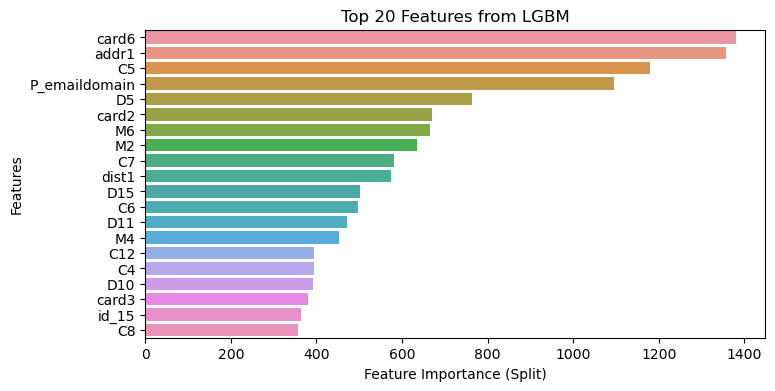
Feature Importance Comparison
- Look further into feature importance from two models. Overall, number of splits is much lower from LGBM while the total gain of certain features is much higher, which also indicates LGBM split the decision tree more efficiently to reach relatively same result.
- There are quite a few feature overlaps between two models, top features with high total gain as well as high number of splits, such as
card6(card type),card2(card number),P_emaildomain(purchaser email address),C5&C7(counting informaiton) are both identified from both models. - Impactful features, such as
V264, which is an engineered feature ranks the top in both models, however, the number of splts is not among the top, indicates the significant impact of this feature on the target. It would be worth further looking at the split nodes of this feature.
| Feature Importance (XGBoost) | Feature Importance (LGBM) |
|---|---|
 |
 |
 |
 |