Silei Huo

Data-driven problem solver with extensive experience in Banking and Technology (Payments), focusing on Strategic Planning, Product Management, and Data Analytics. MBA from London Business School.
Data Science | FinTech | Payment Processing | Banking
View My LinkedIn Profile
Credit Risk Modeling
Utilizing tree-based model (XGBoost) to predict credit risk (probability of default) for loans, leveraging interation_constraints to improve interpretability of the model and tree structures, and exploring scorecard feature development based on feature importance and tree plot.
Part 1: Data Cleaning & EDA
Dataset contains 233,154 rows and 41 columns. The target variable is loan_default (0: non-default, 1: default). The dataset contains both numerical and categorical features.
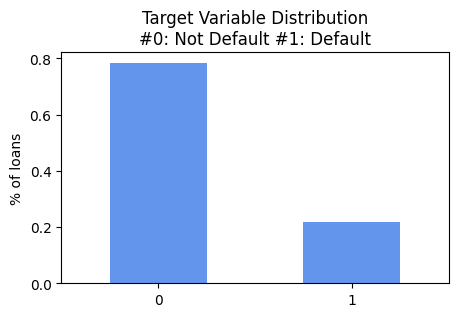
Target Variable Distribution
Default Rate: 21.7%, which is a highly imbalanced dataset, and tree-based model is a good choice for this type of dataset.
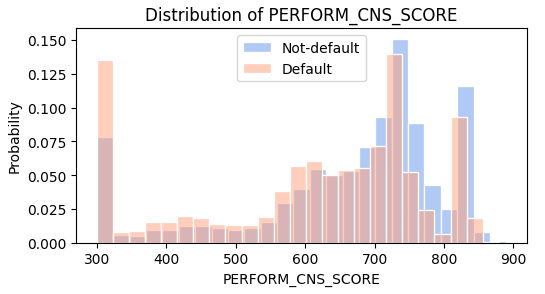
Key Independent Variable Distribution
Below are the distribution of two key independent variables: “credit score” and ltv (loan to value ratio), it shows that the default rate is higher for lower credit score and higher ltv.

Part 2: Model Development & Interpretation
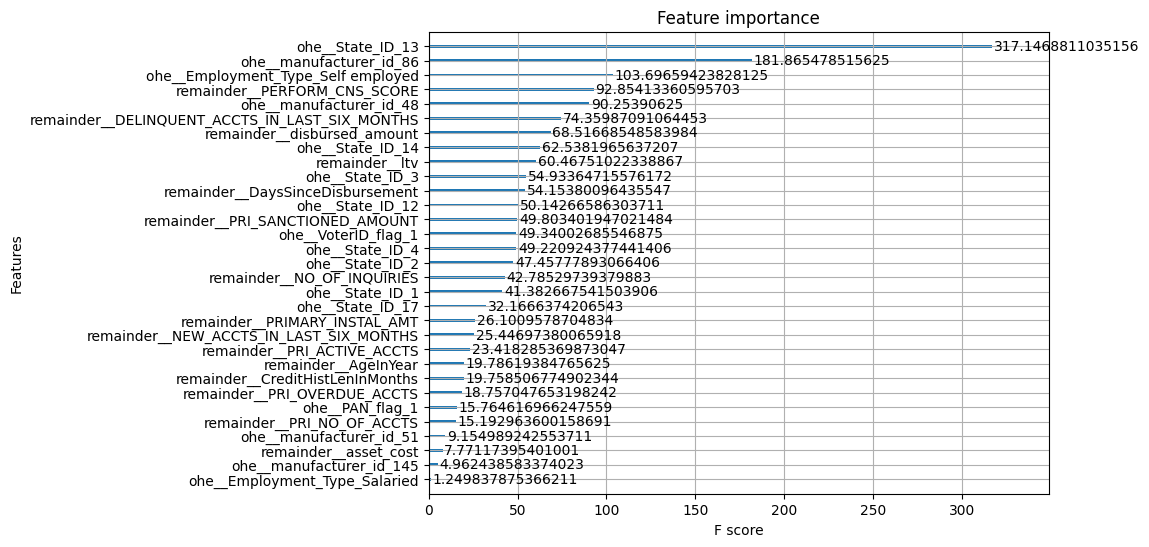
Feature Importance
The top features based on weight(left) and gain(right) are shown below. The top features are consistent between weight and gain, and the top features are ltv, PERFORM_CNS_SCORE, DELINQUENT_ACCTS_IN_LAST_SIX_MONTHS, disbursed_amount, which are also consistent with the EDA findings.

Tree Plot
Below are the tree plots for the top features. The tree plots show that the default rate (gain for leaf) is higher for lower credit score and higher ltv, and shows the structure (split noeds) of the tree, which can be used to develop scorecard.
Credit Score - Node Split

LTV - Node Split

Dataset source: Kaggle
Notebook is inspired by GTC 2021 Building Credit Risk Scorecards Demo